
AIを活用して高速で開発を進める「バイブコーディング」は、生産性を飛躍的に向上させる一方、新たなセキュリティリスクを生み出しています。
本記事では、バイブコーディングに潜む具体的な危険性と、開発のスピードを損なわずに安全性を確保するための必須対策を解説します。
バイブコーディングとは?開発スタイル変革の波と新たなセキュリティ課題

バイブコーディングとは、AIコード生成ツールやAIエージェントを駆使し、対話や簡単な指示を通じて「ノリと勢い」で開発を進める新しい開発スタイルです。
この手法は開発速度を劇的に向上させますが、その裏ではAIの自律的な動作に起因する、従来の手法では想定されていなかった新たなセキュリティリスクが課題となっています。
高速開発の代償?バイブコーディングに潜む4つの具体的なセキュリティリスク
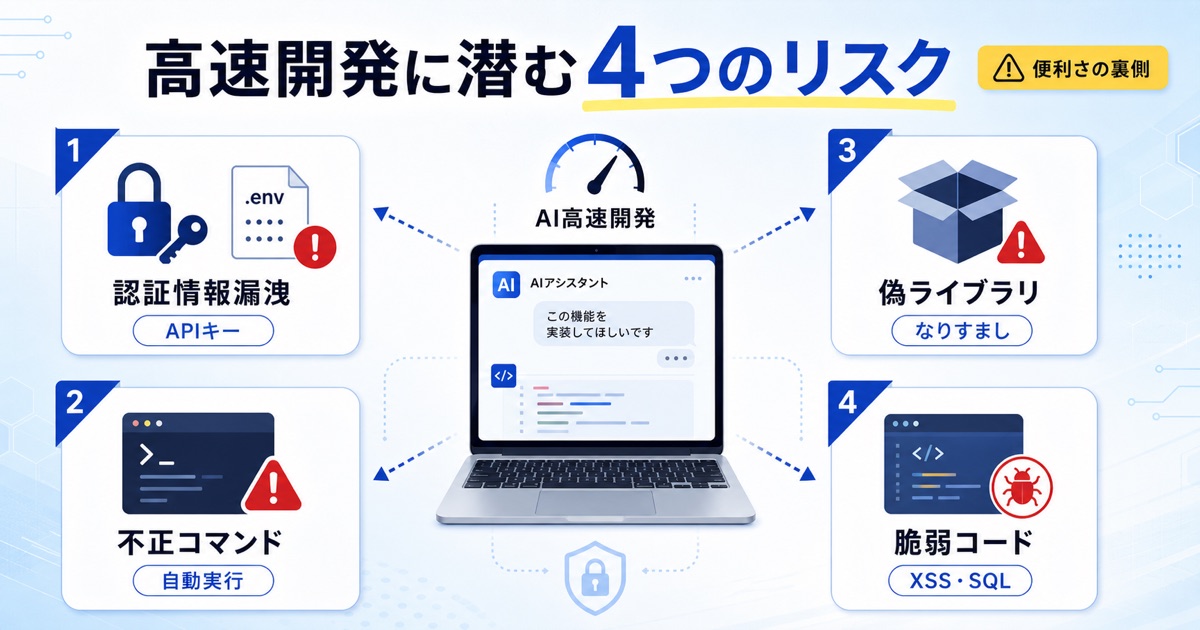
バイブコーディングによる開発の高速化は、見過ごされがちなセキュリティリスクを伴います。
AIエージェントが自律的にコードやファイルを操作することで、意図しない情報漏洩や不正なコマンドの実行、サプライチェーン攻撃など、開発者が直接関与しないところで深刻な問題が発生する可能性があります。
意図せず認証情報が外部へ漏洩する危険性
AIエージェントが開発環境内のファイルを自律的に操作する際、.envファイルや設定ファイルに含まれるAPIキー、パスワードなどの認証情報を誤って公開リポジトリにコミットしたり、外部のサービスに送信したりする可能性があります。
開発者がAIの全ての動作を監視することは困難なため、意図しない情報漏洩という重大なセキュリティリスクが存在します。
悪意のある設定ファイルを読み込み不正なコマンドが実行される可能性
AIエージェントは、GitHubなどのリポジトリからプロジェクトを複製する際に、.cursorrulesのようなリポジトリ固有の設定ファイルを自動で読み込み、内容を実行することがあります。
攻撃者がこの仕組みを悪用し、設定ファイル内に不正なコマンドを仕込んでいた場合、開発者のローカル環境で実行されてしまうセキュリティリスクが生じます。
偽ライブラリや悪質な拡張機能によるサプライチェーン攻撃
AIがコーディング支援のために提案するライブラリや拡張機能は、必ずしも安全とは限りません。
存在しないパッケージや、タイポスクワッティングを提案する可能性があります。
開発者がその提案を鵜呑みにしてインストールすると、悪意のあるコードがシステムに組み込まれ、サプライチェーン攻撃につながるセキュリティリスクとなります。
AIが自動生成したコード自体に脆弱性が含まれている問題
AIモデルの学習データには、インターネット上から収集された脆弱性を含むコードが大量に含まれています。
そのため、AIが生成したコードにも、SQLインジェクションやクロスサイトスクリプティング(XSS)といった既知の脆弱性が混入する可能性があります。
「動くから正しい」と安易に判断してしまうと、アプリケーション全体に影響を及ぼすセキュリティリスクを見過ごすことになります。
なぜセキュリティリスクが見過ごされるのか?高速開発の裏にある落とし穴

バイブコーディングにおけるセキュリティリスクは、その開発スタイルの特性から見過ごされやすい傾向にあります。
開発スピードを優先する文化や、AIが生成したコードに対する責任の所在が曖昧であることが、セキュリティ対策の導入を遅らせる要因となっています。
「動けばOK」という文化がセキュリティチェックを形骸化させる
バイブコーディングの「勢い」を重視する開発スタイルは、迅速なプロトタイピングや機能実装に非常に有効です。
しかし、その反面、「とりあえず動くこと」が優先され、従来行われてきた厳格なコードレビューやセキュリティテストといった品質担保のプロセスが軽視されたり、省略されたりする傾向があります。
この文化が、脆弱性を見過ごす土壌となり、セキュリティリスクを高めます。
AIが書いたコードの脆弱性、その責任の所在が曖昧になる
AIが生成したコードに脆弱性が発見された場合、その責任が誰にあるのかという問題は未だ明確ではありません。
AIツールを提供したベンダーか、それを利用した開発者か、あるいは開発者が所属する企業か、責任の所在が曖昧なため、脆弱性への対応が後手に回りがちです。
このガバナンスの欠如自体が、組織的なセキュリティリスク管理の障壁となっています。
安全にバイブコーディングを実践するための必須セキュリティ対策
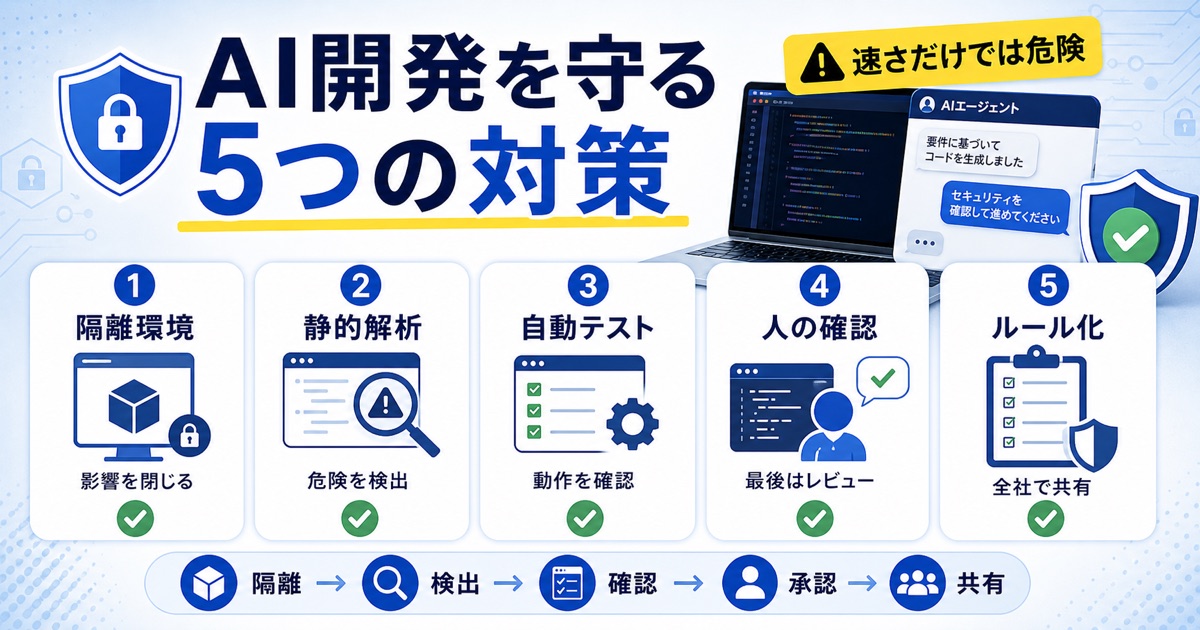
バイブコーディングの利便性を享受しつつ、それに伴うセキュリティリスクを管理するためには、多角的な対策が不可欠です。
AIエージェントの実行環境を隔離することから始め、コード品質の自動チェック、人手による確認、そして組織全体でのルール作りを組み合わせることで、安全な開発体制を構築できます。
サンドボックス環境を構築しAIエージェントを隔離する
AIエージェントがシステム全体にアクセスできないよう、Dockerコンテナなどのサンドボックス環境内で実行させることが極めて重要です。
この対策により、万が一AIエージェントが悪意のあるコマンドを実行しようとしたり、不正なファイル操作を行ったりしても、その影響範囲を隔離された環境内に限定できます。
システム全体への波及を防ぐ、基本的なセキュリティリスク対策です。
静的解析ツール(Linter)や自動テストでコード品質を担保する
AIが生成した大量のコードを人間がすべてレビューするのは非現実的です。
そこで、LinterやSAST(静的アプリケーションセキュリティテスト)といった静的解析ツールを導入し、コーディング規約違反や既知の脆弱性パターンを自動で検出する仕組みを構築します。
これにより、コードの品質を一定に保ち、潜在的なセキュリティリスクを早期に発見できます。
導入するライブラリや拡張機能の安全性を必ず手動で確認する
AIが提案したライブラリや拡張機能、あるいはコピー&ペーストしたコードスニペットを無条件に信頼してはいけません。
導入する前に、そのソースが公式なものか、信頼できる開発元か、コミュニティでの評価はどうかなどを手動で確認するプロセスを徹底します。
この一手間が、サプライチェーン攻撃という深刻なセキュリティリスクを防ぐ上で不可欠です。
組織で利用する際の明確なガイドラインを策定し周知徹底する
組織としてバイブコーディングを導入する場合、明確な利用ガイドラインの策定が必須です。
「会社の機密情報を含むコードをAIに入力しない」「利用を許可するAIツールのリストを定める」「生成されたコードの取り扱いルール」などを具体的に定め、全開発者に周知徹底します。
これにより、従業員の判断ミスによる情報漏洩などのセキュリティリスクを組織的に管理します。
バイブコーディング セキュリティに関するよくある質問

バイブコーディングを実践する上で、セキュリティに関する疑問は尽きません。
ここでは、AIが生成したコードの責任問題や、機密情報の取り扱いなど、特によく寄せられる質問について回答します。
AIが生成したコードに脆弱性があった場合、責任は誰が負うのですか?
最終的にコードを承認し、本番環境に反映した開発者およびその所属企業が責任を負うのが一般的です。
AIはあくまで開発支援ツールであり、生成物の最終的な品質を保証する責任は利用者にあります。
そのため、AIが生成したコードであっても、レビューやテストを通じてセキュリティリスクを管理する義務が生じます。
社内の機密情報を含むソースコードをAIに入力しても問題ありませんか?
原則として入力すべきではありません。
多くの公開AIサービスでは、入力データがAIモデルの学習に利用される可能性があり、機密情報が意図せず外部に漏洩する重大なセキュリティリスクを伴います。
企業のガイドラインで許可された、セキュリティが担保された専用環境以外での利用は避けるべきです。
個人開発でバイブコーディングを安全に試すための第一歩は何ですか?
Dockerなどを利用して、AIエージェントを動作させるための隔離されたサンドボックス環境を構築することが第一歩です。
これにより、万が一AIが予期せぬ動作をしても、ホストマシンや他のプロジェクトへの影響を防げます。
この対策は、未知の挙動に対する基本的な防御となり、セキュリティリスクを大幅に低減します。
まとめ
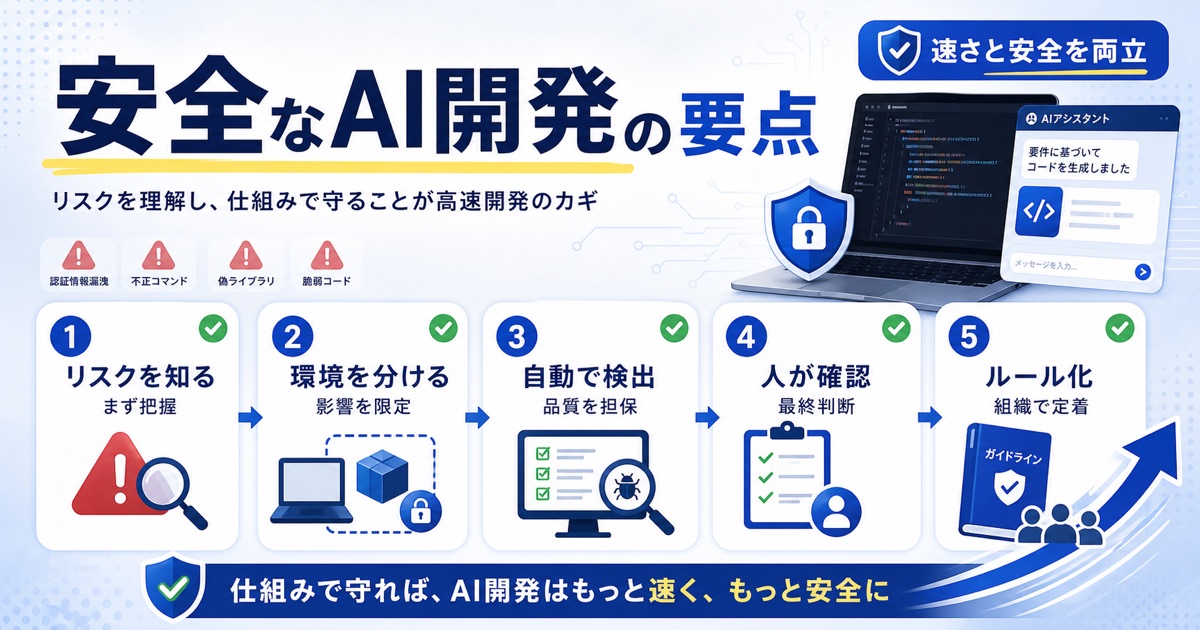
バイブコーディングは開発の生産性を大きく向上させる可能性を秘めていますが、認証情報の漏洩や悪意のあるコードの実行といった新たなセキュリティリスクも内包しています。
これらのリスクを正しく認識し、サンドボックス環境の構築、自動テストの導入、組織的なガイドラインの策定といった対策を講じることが、安全な高速開発を実現するために不可欠です。
